Welcome to Open Davidson
Open Davidson provides keyword searching of all The Davidsonian issues published between 1914-2010.
These operators can be used between search terms: AND (default),
OR, NOT, NEAR. These operators
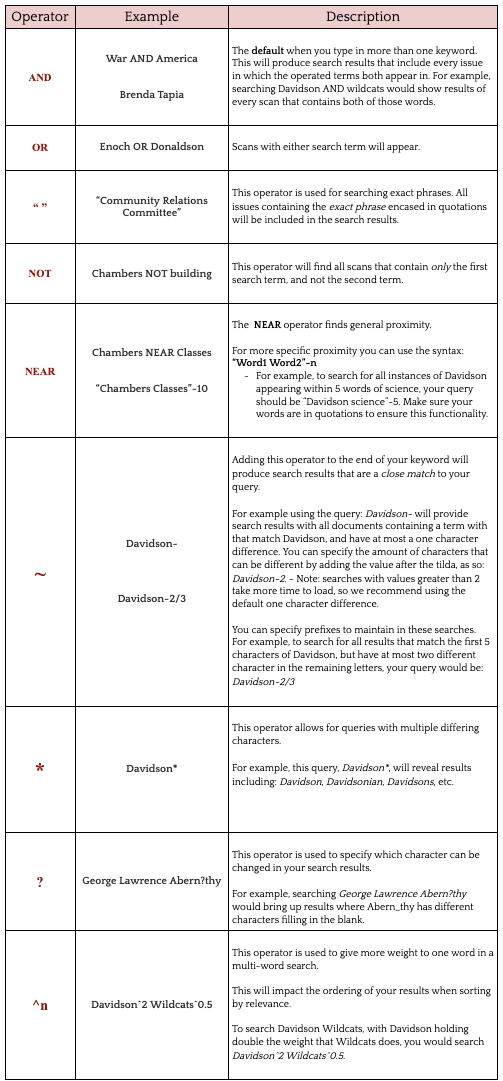
must be capitalized to be used properly. For information on advanced search operators available in this tool,
see the Instructions section listing all available search operators
We highly recommend that while conducting your research with this tool, you look at the original documents
for official reference. Although we are very confident in the accuracy and readability of our text files,
they may contain a small percentage of errors. Therefore, when citing or drawing important conclusions,
look through the OCR’d PDF by clicking the “View Page” link and visit the original source in the Davidson
College library by clicking “View Issue.” To learn more about how these text files were generated and how
errors were corrected, please refer to the "About the Project" page.
"Some of the terminology used is reflective of the language used historically by members of the Davidson community.
These terms may be, but are not necessarily, outdated, offensive, and/or harmful. While we would not use this
terminology today, it is important to search for these terms in historical documents to surface valuable information
for researchers today." (Davidson College Archives, 2024)
Wondering Where to Start?
For a list of commonly searched terms to help your research, visit our controlled vocabulary page.
For more advanced search functionality, please visit the advanced search tab.
Advanced Search
This search function grants you more ability to filter and contextualize your search.
Use the "Date From" and "Date To" inputs to specificy what
time period you want your results to include.
Further, you may input the amount of "Context Lines" you want to reveal around your
keyword. Context lines control the amount of text revealed before and after your query. Higher
context line inputs will reveal more of the surrounding text for any given search. There is a
limit of 20 context lines for any search.
About the Project
With the commencement of the
Commission on Race and Slavery
in 2017, Davidson College has received many requests from African American descendant
community members wanting to learn about their heritage dating from slavery to
the late twentieth century. One important source of information came from The
Davidsonian, a student publication that served as both a local and school news
source for many years. From important historical events to simple visitors’
reports, The Davidsonian is often a starting point for historical researchers.
However, this valuable information seemed to be lost as there was no way to
search through the documents without manually reading every issue. To make it
easier for both researchers and family members seeking information about loved
ones, the 2024 Community Research Fellows were tasked with coming up with a
digital tool that could assist with historical research of Davidson College.
The goal of our project is to make Davidson’s history easily accessible to all.
Our student, faculty, and staff team took a deep dive into Davidson College history,
including its connections to slavery, and how that history has shaped the community
around the college. In collaboration with historian Hilary Green and the Davidson
College archives, our team has created text files and searchable pdfs out of the
Davidsonian. In addition, we have built this website to enable both simple and
advanced searches across all the pages. Throughout this process, our team has
learned and applied computational techniques and tools, including image binarization,
OCR, generative AI assistants, APIs, and RAG, and learned about the Digital Humanities
field as a whole. We hope that more people will be able to gain valuable information
about Davidson’s history by using this website.
Methodology
The goals of this project were to create searchable pdfs and readable text files from the
Davidson scans currently housed in the Archives system. The central process in this goal was
Optical Character Recognition (OCR). OCR refers to the process that converts
an image of text into a machine-readable text format. Our project's aim was to use OCR to
create searchable PDFs as well as a corpus of text files containing all the contents of the
Davidsonian. With this corpus, we would be able to create a search tool to increase the
accessibility of Davidson's history to researchers, families, and community members.
The OCR process necessitated subprocesses before and after, known as preprocessing and
postprocessing. Both of these subprocesses are intended to increase the content captured and
the accuracy of the text in our final text files. Accuracy measurements and tests were based
on 5 ground truth documents, or pages of the Davidsonian that were manually typed out.
Our workflow is briefly explained in the following sections.
Pre Processing
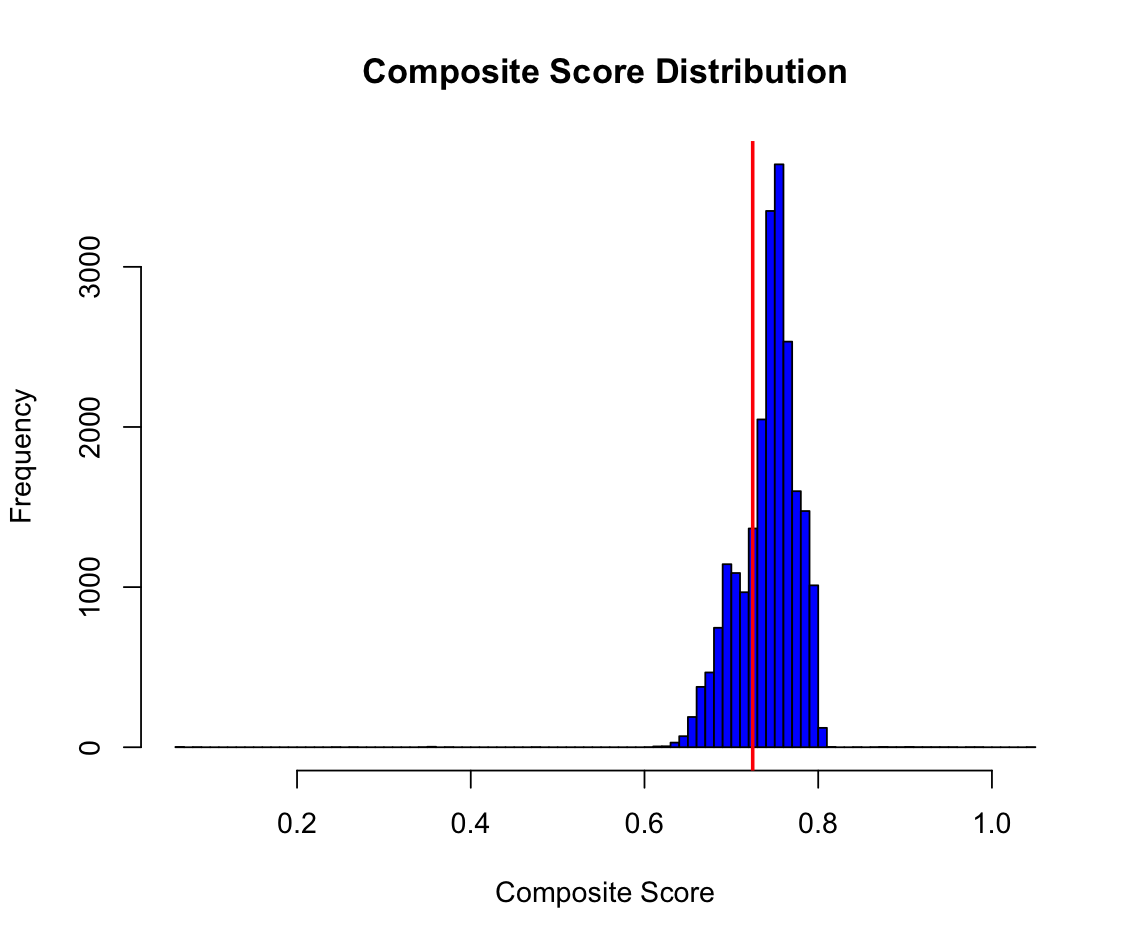
Our preprocessing methodology required us first to classify scans according to their quality.
Using the in-depth data that we collected on each scan, we constructed a composite score to
compare across all the documents. If any document fell below a specified threshold, we deemed it a
low-quality scan.
Because preprocessing methods are intended to eliminate the image quality errors
that may worsen OCR quality, we only wanted to pre-process scans we deemed as low-quality.
In the image above, you can see one of our most extreme examples of this binarization process
from a page of the January 15, 1920 Davidsonian issue. On the left you will see the original document,
and on the right you will see the binarized version.

Once we identified the low-quality scans, we ran each of them through a binarization process adapted from
the Berlin State Library. The binarization
process greatly increased the amount of text captured from low-quality scans in the OCR process.
OCR
The second step of our process was to run all 23,000 documents through Tesseract,
an open-source OCR engine by Google that recognizes and extracts text from documents.
Through our research, we found Tesseract to be the most accessible and useful tool for our project. For each scan (inputted as a tif file) we produced
a searchable pdf and a text file. Although the text files were comprehensible and had respectable
levels of accuracy, there were still areas obfuscated by miscellaneous characters or errors in the text.

See the above image for a side-by-side comparison of what
Tesseract produced (left) versus what should have been produced, also known as the "Ground Truth" (right).
To correct these errors and increase the accuracy of the text files, we began investigating methods of
postprocessing to refine the files produced by Tesseract.
Post Processing
To finalize our text files, we investigated ways to reduce error rates after the OCR process. We needed an automated
way to identify and fix spelling errors, ambiguous characters and spacing, as well as formatting mistakes. Text generative and
instruction-fine tuned large language models were the most promising tool that emerged from our investigaiton. We evaluated the
feasibility and effectiveness of both open-source models and paid tools. We were granted access to Davidson's
GPT 4.o workspace, allowing us to explore the ways OpenAI's model
could serve as a post-processing tool. Weighing open-source models against OpenAI's functionality showed us that we do
not have the computing resources to run a large, open-source LLM of comparable efficenty to GPT on our local computers.
Exploring OpenAI as a post-processing tool required extreme intentionality to prevent hallucinations from the model and increase
the reliability of the output. To prevent hallucinations, we crafted thoughtful prompts (instructions to our model) and tested each of
them against our ground-truth documents. To increase reliability, we minimized the temperature of the model, which can be explained as the
randomness or creativity of the model. To prevent any changes to names or historically significant fields, we also fed our controlled vocabularly
into our model's knowledge base and instructed it to preserve those fields with special care.
Tool Building
The final product of our research was this search tool, Open Davidson. Our goal was to increase the accessibility to the Davidsonian’s
contents and guide users to the original source. Our site uses Whoosh (a fast, pure Python search engine library)
to search the database of over 20,000 text files for user queries. We developed algorithms to match specific lines with
user queries as well, allowing users to see the context around their query in each document. Additionally, we provide
users with links to the scanned pdf of the page, and the tif file of the entire issue for their reference. We give users
the ability to search complex queries using a vast supply of operators and filters as well as sorting options for the
search results. To assist in the management of advanced research projects, our site offers the option to save each query’s
results as a csv file for storage and later reference.
Open Davidson

We named our project "Open Davidson" to honor several inspirations.
The most direct link is to OpenAI, whose tools we used for post-processing
all our documents. Our success also relied heavily on open source software,
which was essential for our pre-processing and OCR steps and freely available
to the public. Additionally, Open reflects our mission to Open The Davidsonian,
making information readily accessible to everyone.
Meet the Team
2024 Community Research Fellows
Community-based research (CBR) is “a form of investigation in which the question to be studied arises from the needs of a group of
individuals, such as undocumented workers or people who are homeless; from a concern of a nonprofit organization;
or from the interwoven social challenges a geographic or other type of community faces (Beckman & Long, 2016, p. 1).”
Over the past 10 years, the Center for Civic Engagement at Davidson has played a central role in several community needs
assessments and facilitated community-based research projects through academic courses in partnership with faculty.
In 2010, the Associate Dean served on the advisory board for the Lake Norman Area Community Needs Assessment and then
the Center engaged students and faculty in ongoing updates to the 2010 structure in 2014 and 2018. In the summer of 2020,
the Center for Civic Engagement and faculty in the Data CATS program collaborated to launch
the community research program
that engages students in place-based community research.
This year, the Community Research Fellows took a deep dive into Davidson College history, including its
connections to slavery, and how that history has shaped the community around the college. In collaboration
with historian Hilary Green and the Davidson College archives, we scraped digital assets, including the
Davidsonian, and built this tool that makes it easy to search, summarize and analyze them.

Hannah Holmes Class of 2026
Hannah is an Anthropology Major, Data Science Minor from Beaumont, Texas.
During the academic year, she works in the Archives and actively participates in the Dionysia theater club.
She has greatly appreciated the interdisciplinary nature of the project and the opportunity to explore the
Davidsonian. Hannah is thrilled to present this tool to the community and takes immense pride in the achievements
of the team.

Kerem Atas Class of 2026
Kerem is a Computer Science Major, Data Science Minor from Bursa, Turkey.
On campus, he works for Davidson Outdoors and for the Department of Mathematics and Computer Science.
He is interested in applying tools and methods of data science to understand contemporary socio-political issues.

Mary Elizabeth Shoop Class of 2026
Mary Elizabeth is a Political Science Major, Data Science Minor
from Asheville, NC. On campus, she works in the Writing Center, grades for the Computer Science Department,
and runs on the Cross Country and Track teams. She has experience working on congressional campaigns, in policy research,
and with public opinion polling.

Philo Gabra Class of 2025
Philo is a Computer Science Major, Data Science Minor from Cairo, Egypt. On campus,
he works for Davidson Technology & Innovation (T&I) as a Student Consultant and for the Department of Mathematics and
Computer Science as a grade. He has been an active member and secretary of the Davidson International Association (DIA). He has
researched and developed in many fields including VR, machine learning, mobile development, etc.
Faculty

Dr. Laurie Heyer Associate Dean for Data & Computing, Kimbrough Professor of Mathematics and Computer Science,
Chair of Genomics
Laurie J. Heyer is the John T. Kimbrough Professor of Mathematics and Computer Science,
Associate Dean for Data and Computing, and co-director of the Community Research Fellows program at Davidson College.
She has co-authored two biology textbooks and conducts collaborative research with students and colleagues in data science.

Dr. Aubrey Condor Former Assistant Professor of the Practice of Data Science
Aubrey Condor is a data scientist and
researcher specializing in the use of artificial intelligence for educational applications. She previously taught courses at Davidson
college as part of an interdisciplinary data science minor.

Dr. Hilary Green James B. Duke Professor of Africana Studies
Hilary N. Green is the author of Educational
Reconstruction: African American Schools in the Urban South, 1865-1890 (Fordham University Press, 2016) and Unforgettable
Sacrifice: How Black Communities Remembered the Civil War (Fordham University Press, 2025).

Dr. Stacey Reimer Associate Dean of Students, Director of the Center for Civic Engagement
Stacey has over 30 years
of experience in higher education as a practitioner and faculty member. At Davidson, she provides strategic direction, supervision and management
for the areas of civic engagement, leadership development, experiential learning, student activities and the college union. Immediately prior to
coming to Davidson, she served as a lecturer in the Higher Education graduate program at Syracuse University and was involved with the development
of innovative curricula around learning communities, community-based learning, and critical reflection. Each semester she teaches a seminar on high
impact experiential learning.
Special Thanks to
Library Staff
Melissa Anderson Systems and Discovery Librarian
Jessica Cottle-Hart Justice, Equality, and Community Archivist
Jacob Heil Assistant Director of Digital Learning
Molly Kunkel Digital Archivist
James Simon Assistant Director of Collections & Discovery
Sara Swanson Assistant Director of Archives, Special Collections, and Community
Davidson T&I
Luke Aeschleman Cloud Solutions Architect
Michael Blackmon Instructional & Research Computing Systems Administrator
Kathi Brooks Application Analyst, Collaborative Apps
John McCann Director of User Services and Experience
Additional
Funding through the Community Research Fellows Program, with support from Davidson College and the Bonner Foundation
Stella Mackler (and the 100+ years of student journalism that made this project possible!) Class of 2026,
Editor-in-Chief of the Davidsonian
Software Developers Tesseract, sbb_binarization, OpenAI Assistant API

{kind=link}